
Jeg havde engang en kollega, Peter, som plejede at sige: Enterprise betyder 'svært at installere'. Så har vi definitionen på plads. Og det er jo ikke helt løgn.
Med en stor monolit opgiver man næsten at tænke i continuous delivery, før man overhovedet kommer i gang.
- Det er kun noget, man kan gøre på ny teknologi.
Eller hvad?
Med lidt stædighed og knofedt kan det faktisk også lade sig gøre på ældre teknologi. Også selvom teknologi, som er 10 eller 15 år gammel, er fra en tid, hvor enterprise vitterligt betød 'svært at installere'.
En af vores applikationer er en monolit. En stor, fed, dejlig enterprise-monolit. Svær at installere. Et grundlæggende godt system, der blot er blevet lidt gammelt.
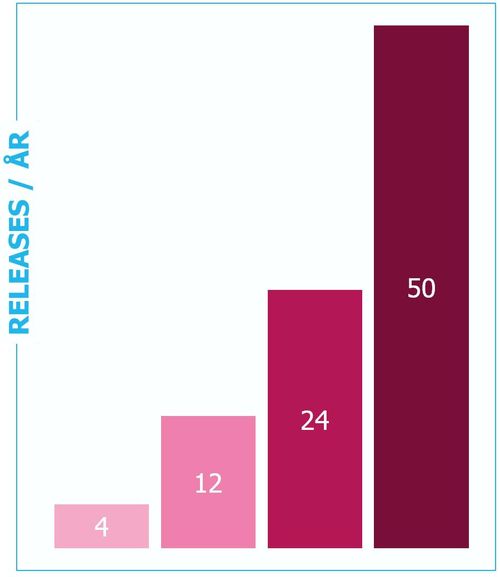
Derfor plejede vi kun at release 4 gange om året.
Men vi deployer faktisk systemet 50 gange om året i dag. Det her er historien om, hvordan vi kom fra 4 til 50 - ikke på en moderne cloud-teknologi - men på en god gammeldags enterprise "svær-at-installere" applikation.

Læs også: Vi deployer 2.000 gange i år - det handler om mennesker før teknologi
Har du læst om, hvordan vi lykkedes med at gennemføre små forandringer i vores software?
Trin 1: Dokumentation
Problem: Kun eksperterne kan installere.
Løsning: Dokumenter installationen så udførligt, at en person uden kendskab til applikationen kan installere den.
Vores første udfordring var, at det kun var nogle ganske få eksperter, der kunne installere applikationen. Det gjaldt også opgraderinger. Løsningen på det var forholdsvis simpel. Vi dokumenterede i høj detaljegrad, hvordan man installerede. Dokumentationen bestod af flere ting. Det var ikke sådan, at vi ikke havde dokumentation allerede, men vi højnede niveauet i et omfang, så resultatet blev en installationsproces, der var så veldokumenteret, at den i princippet ville kunne automatiseres.
Vi udarbejdede dels en "spiseseddel", hvor man kunne afkrydse, hvad man ville installere, for det var ikke nødvendigvis alle dele af systemet, som altid var inkluderet i installationen. Vi definerede også, hvilke efterfølgende tests, det var nødvendigt at afvikle for at vide, at installationen var forløbet godt. Det kunne både være manuelle tests og tekniske verificeringer. Endelig lagde vi installationen ud til en helt anden medarbejderfunktion og ændrede vores proces, så "de nye medarbejdere" både skulle gennemføre installation på præ-prodmiljøet, der blev en slags generalprøve for dem, og efterfølgende gennemføre installationen i produktion.
Foruden spisesedlen var alle udviklere forpligtet til at notere præ- og post-steps, der var specifikke for den enkelte release, i en releasemanual. Det kunne fx være et oprydningsscript relateret til en fejlrettelse, som først skulle afvikles efter release.
Trin 2: Optimering: Hurtigere og mere stabil installation
Problem: Eksperterne vidste, at nogle gange skulle man liiiige.
Løsning: Vi investerede i at optimere installationsprocessen.
Da først installationsarbejdet var dokumenteret så tydeligt at andre end eksperterne kunne gennemføre en installation, blev det hurtigt tydeligt, hvor processen skulle optimeres. For de nye installatører havde ingen forudsætninger for at kende specielle tricks eller andre symptomer på, at en installation ikke forløb planmæssigt.
Resultatet blev, at vi foretog en række investeringer i at optimere installationsprocessen. Det betød bl.a. at installationstiden blev forkortet, at udvalgte ting kunne køre parallelt, og at installationsprocessen blev mere robust.
Der var ikke tale om store investeringer, men det krævede højt specialiserede kompetencer at lykkes med de særlige tricks, som løftede installationsprocessen.
Trin 3: Granulerede deploys
Problem: Det fulde deploy var for risikabelt.
Løsning: Vi splittede det fulde deploy op i mindre selvstændige deploybare enheder.
Det her trin var ikke strengt nødvendigt, og vi havde det nok mest, fordi det var et nemt skridt for os. Husker du spisesedlen? Spisesedlen gav os faktisk mulighed for at deploye enkelte services uafhængigt af den store monolit. Nogle af elementerne kunne vi endda deploye i den normale forretningstid midt på dagen - hvis vi altså turde.
Pointen var, at vi ikke behøvede at deploye det fulde system hver gang, og at vi begyndte at opnå mere detaljeret viden om, hvordan de enkelte elementer på spisesedlen opførte sig, når vi installerede dem.
Det betød, at vi kunne foretage mindre deploys i hverdagen - hotfixes - uden at deploye den fulde applikation.
Trin 4: Fra weekend til hverdage
Problem: Vi kunne kun deploye den fulde applikation i weekenden.
Løsning: Just do it.
Da vi først havde installationen oppe at køre forudsigeligt, var det næste trin at kunne deploye det fulde system i hverdage. Vi havde været nervøse for, om vi kunne nå at gennemføre et fuldt deploy på en hverdag - især hvis der gik noget galt, og derfor havde vi altid holdt det til weekender.
Første gang vi deployede en hverdag, var efter månedsvis - eller måske endda årevis - af frygt og hvad-nu-hvis'er. For - ja - hvad nu hvis? Hvis vi ikke var færdige til midnat, hvor længe kunne vi så blive ved? Og ville systemet overhovedet være oppe at køre næste morgen?
Vi havde med tiden oparbejdet en vis erfaring med stabile deploys i weekenden, og vi havde afkortet deploytiden væsentligt. Derfor besluttede vi os til sidst for, at vi godt turde prøve. Vi valgte et tidspunkt, hvor kundeaktiviteten var lidt mindre end normalt - en stille periode om sommeren, hvor katastrofen ville være markant, men ikke uoverstigelig, hvis vi fx var nede hele næste dag. Og hvordan gik det så?
Dårligt. Det gik virkelig ikke godt. Vi havde overset et skeduleret job, som kørte på vores produktionsmiljø hver aften kl. 20, og som betød, at hele installationen mislykkedes. Vi sad til langt ud på aftenen for at rede trådene ud, og først omkring midnat kom vi i mål. Men vi kom i mål. Og næste dag kørte systemet, så vi undgik nedetid.
Vi havde selvfølgelig fået sat os en skræk i livet, men vi var sluppet fra det med æren i behold. Og hvad så? Skulle vi give op og konstatere, at det var for risikabelt at deploye i hverdagen, eller skulle vi fortsætte? Det overvejede vi. Men vi valgte at tro på, at vi var stødt ind i det ene problem, der var potentielt blokerende, så vi fik flyttet det nederdrægtige job, og så fortsatte vi vores fulde deploys på hverdage.
Og det virkede!
Det var en kæmpe milepæl for os, for herfra begyndte det at gå hurtigt. Nu kunne vi faktisk deploye i hverdagen, selvom det var om aftenen efter vores normale arbejdstid.
Nu var fulde detploys ikke kun hver 3. måned, men det var måske en gang om måneden eller deromkring, at vi kunne release: en faktor 3 forbedring fra 4 til 12 gange om året. Fedt!
Det var skelsættende; ikke blot fordi vi nu kunne få funktionalitet ud til brugerne hyppigere, men også fordi det begyndte at ændre vores arbejdsgange. Tidligere havde en fuld release betydet en hel måneds feature freeze med regressionstest og andre releasebesværgelser. Men i og med, at vi begyndte at deploye oftere og dermed mindre releases, havde vi nu også releases med langt mindre testarbejde.
Trin 5: Fra månedlige til 14-dages releases
Problem: Vi havde stadig test-tunge feature freeze-perioder.
Løsning: En forudsigelig og hyppig releasekadence hver 14. dag.
Vi havde arbejdet med en intern ambition om at opnå continuous delivery. Da vi skød det projekt i gang, viste det sig, at det gamle legacy-system blev det første i hele virksomheden til at opnå faste 14-dages releases. Intet system blev releaset oftere på det tidspunkt. Det var langt foran systemer på langt mere moderne cloud-teknologi, som burde have været skræddersyet til at lægge sig i førersædet i deploy-hastighedskampen.
Hvorfor nu det? Hvorfor kunne vi lykkes med at deploye en gammel legacy-applikation langt oftere end de nye teknologier?
Først og fremmest takket være udviklerne på systemet - de ville lykkes med det. Det var så fedt at opleve. De kunne have brugt alle tekniske undskyldninger for at lade være og lade cloud-teamsene rode med de hyppige releases, men det gjorde de ikke.
Men de havde faktisk også en lille fordel. Fordi netop dette system havde årevis af modning, tydelige processer, kvalitetssikringsprocedurer osv. at basere sig på. Moden teknologi, som vi har passet godt på, er vitterligt modent. Ikke "bare" gammelt. Og det har fordele. For os betød det, at vi hver 14. dag kunne gennemføre en fuld release af systemet.
Det ændrede dramatisk på vores opfattelse af kvalitetssikring. Vi stoppede med at operere med lange feature freeze-perioder, for vi var i langt mere granuleret kontrol over, hvad vi releasede, og hvis der skulle smutte en fejl med ud, var det både hurtigere at identificere fejlen, men selvfølgelig også hurtigere at få den ud - man skulle højest vente 14 dage.
Trin 6: Optimering: Feature-toggle framework
Problem: Hvad nu hvis noget ikke er klar til release?
Løsning: Et feature-toggle-framework satte os i stand til at undtage ting fra release.
På dette tidspunkt havde cloud-teamsene for længst overhalet legacy-systemet. Nu deployede vi cloudløsninger 10-20 gange om dagen, imens den gamle monolit fortsat kun blev deployet hver 14. dag.
Men nogle af metodikkerne fra cloud-udviklingen gled også ind i monolitten. Fx vores feature-toggle-framework. Med det kunne vi slå features til og fra på kundeniveau. Det betød også, at vi kunne forsimple vores branching, og at vi begyndte at kunne teste ting i produktion, som kun var slået til for vores egne medarbejdere.
Trin 7: Ugentlige deploys
Problem: Vi fik en hård deadline.
Løsning: Vi releaser hyppigere.
På et tidspunkt løb vi ind i en hård deadline, som vi skulle finde en løsning på at overholde. Vi tog forskellige tiltag, og et af dem var at hæve releasekadencen fra hver 2. uge til hver uge.
Nogle teams ville måske sige: Så har vi ikke tid til at release - nu må vi release sjældnere. Vores erfaring sagde os, at vi skulle gøre det modsatte - release endnu hyppigere.
Det krævede yderligere investering i automatikker og forsimpling af releasedokumentationen, men det lykkedes faktisk.
Så nu deployer vi et 10-15 år gammelt system hver eneste uge. Og vi er gået fra 4 til 50 idriftsættelser om året.
Hvad betyder det så?
Lead-time er den tid, man måler fra en opgave påbegyndes, og indtil den er i produktion.
I gamle dage tog en opgave os gennemsnitligt 22 dage. Herefter tog det i værste fald 4 måneder at deploye (3 måneders release-cyklus + 1 måneds feature freeze). Man kunne altså risikere at en triviel opgave hurtigst ville kunne idriftsættes om 5 måneder.
Nu tager en opgave os gennemsnitligt 11 dage. Og i værste fald tager den 1 uge at release. Man kan altså i værste fald risikere at en gennemsnitlig opgave idriftsættes på 18 dage. På et komplekst legacysystem.
Det betyder, at time-to-market er forbedret dramatisk - på en moden platform, der burde være svær at installere.
Uden dem kunne vi ikke
Den usagte forudsætning er naturligvis medarbejderne. For som det meste legacy-software kan vi ikke frigive i dagtimerne. Det kræver, at nogen arbejder i servicevinduer om aftenen.
Og det kan kun lade sig gøre, fordi der er mange medarbejdere, der får det til at passe ind med deres private forpligtelser.
Det er super flot!